"Ảo giác AI" là gì mà Apple cũng chưa thể giải quyết?
CEO Tim Cook thừa nhận Apple Intelligence chưa thể tránh hoàn toàn "ảo giác" - hiện tượng đưa thông tin sai lệch, không có thật.
Được công bố tại WWDC 2024, Apple Intelligence là loạt tính năng trí tuệ nhân tạo (AI) trên iPhone, iPad và máy tính Mac, có khả năng tạo nội dung, hình ảnh và tóm tắt văn bản.
Tương tự những hệ thống AI khác, nhiều người đặt câu hỏi về hiện tượng ảo giác với Apple Intelligence. Dựa trên chia sẻ từ CEO Tim Cook, AI của Táo khuyết chưa thể loại bỏ hoàn toàn tình trạng này.

CEO Tim Cook trong một buổi phỏng vấn ngay sau sự kiện WWDC 2024. (Ảnh: Marques Brownlee/YouTube).
Trong cuộc phỏng vấn với The Washington Post, Cook thừa nhận "chưa từng khẳng định" Apple Intelligence hoàn toàn không tạo ra thông tin sai lệch hoặc gây hiểu lầm.
"Tôi nghĩ chúng tôi đã hoàn thành mọi thứ cần làm, bao gồm cân nhắc kỹ mức độ sẵn sàng áp dụng công nghệ vào các lĩnh vực. Do đó, tôi tin chắc (Apple Intelligence) sẽ có chất lượng rất cao. Nhưng phải thành thật rằng độ chính xác có thể không đến 100%. Tôi chưa từng khẳng định điều này", Cook nhấn mạnh.
Ảo giác AI là gì?
Theo IBM, ảo giác (hallucination) là hiện tượng mô hình ngôn ngữ lớn (LLM) - thường là chatbot hoặc công cụ thị giác máy tính - nhận mẫu dữ liệu không tồn tại hoặc không thể nhận dạng với con người, từ đó tạo kết quả vô nghĩa hoặc sai lệch.
Nói cách khác, người dùng thường yêu cầu AI tạo kết quả chính xác, dựa trên dữ liệu đã đào tạo. Tuy nhiên trong một số trường hợp, kết quả của AI không dựa trên dữ liệu chính xác, tạo phản hồi "ảo giác".
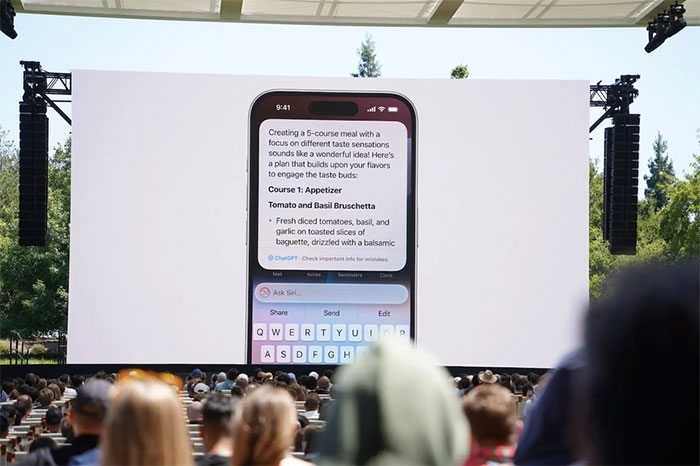
ChatGPT được tích hợp lên Siri kể từ iOS 18. (Ảnh: The Verge).
Ảo giác thường liên quan đến não người hoặc động vật chứ không phải máy móc. Tuy nhiên, khái niệm này cũng được dùng với AI bởi mô tả chính xác cách mô hình tạo kết quả. Nó tương tự cách con người đôi khi thấy vật thể kỳ lạ trên trời, âm thanh không rõ nguồn gốc hoặc thứ gì đó chạm vào cơ thể.
Hiện tượng ảo giác xảy ra do nhiều yếu tố như quá khớp (overfitting), dữ liệu đào tạo sai lệch và sự phức tạp của mô hình. Các AI của Google, Microsoft hay Meta từng gây tranh cãi vì hiện tượng này.
Theo New York Times, chatbot Bard của Google từng nói rằng James Webb là kính viễn vọng đầu tiên chụp ảnh hành tinh ngoài Hệ Mặt trời. Trên thực tế, hình ảnh đầu tiên về ngoại hành tinh đã chụp từ năm 2004, trong khi James Webb phóng vào 2021.
Ít ngày sau, công cụ Bing của Microsoft ghi sai về ca sĩ Billie Eilish. Tiếp đến, ChatGPT bịa ra hàng loạt vụ án không có thật trong lúc giúp luật sư viết tóm tắt pháp lý nộp lên tòa.
Vì sao AI lại ảo giác?
Những chatbot như ChatGPT dựa trên LLM, dữ liệu đào tạo lấy từ các nguồn lớn như trang tin tức, sách báo, Wikipedia và lịch sử chat. Bằng cách phân tích mẫu quan sát, mô hình sẽ tạo kết quả bằng cách dự đoán từ dựa trên xác suất, không phải độ chính xác.
"Nếu thấy từ 'mèo' (cat), bạn sẽ lập tức nghĩ về trải nghiệm và những thứ liên quan đến mèo. Còn với mô hình ngôn ngữ, đó là chuỗi ký tự 'cat'. Do đó, mô hình vẫn có thể lấy thông tin những từ ngữ, chuỗi ký tự xuất hiện cùng", Emily Bender, Giám đốc Phòng thí nghiệm Ngôn ngữ học tính toán - Đại học Washington, giải thích.
Do Internet còn nhiều thông tin sai lệch, chatbot hoàn toàn có thể mắc sai lầm. Tháng 11/2023, Vectara, một startup thành lập bởi các cựu nhân viên Google, công bố nghiên cứu về tần suất đưa thông tin sai lệch của AI.

Một công cụ tóm tắt văn bản của Vectara. (Ảnh: New York Times).
Trong bài nghiên cứu, Hughes và nhóm của ông yêu cầu chatbot tóm tắt bài báo, nhiệm vụ cơ bản và dễ xác minh đúng sai. Kể cả với nhiệm vụ này, AI vẫn liên tục tự tạo thông tin.
Theo đó, kể cả trong tình huống đã phòng ngừa, chatbot vẫn có 3% khả năng bịa thông tin, và cao nhất đến 27%.
Ví dụ, nhóm nghiên cứu yêu cầu PaLM của Google tóm tắt bài báo về người đàn ông bị bắt do trồng "loại cây phức tạp" trong một nhà kho. Trong đoạn tóm tắt, mô hình tự bịa thông tin rằng đó là cây cần sa.
"Chúng tôi đưa 10-20 tin đã kiểm chứng cho các hệ thống và yêu cầu tóm tắt. Vấn đề cơ bản là chúng vẫn có thể tạo ra lỗi", Amr Awadallah, CEO Vectara, cựu Phó chủ tịch Đám mây Google, cho biết.
Tỷ lệ ảo giác của ChatGPT, Apple Intelligence
Trong bài viết liên quan đến mô hình nền tảng (Fundamental Model) của Apple, công ty đề cập thử nghiệm tạo "nội dung có hại, chủ đề nhạy cảm và thông tin sai lệch". Kết quả, tỷ lệ vi phạm của Apple Intelligence khi chạy trên máy chủ là 6,6% trong tổng số yêu cầu, khá thấp so với những mô hình khác.
Do chatbot có thể phản hồi gần như mọi thông tin theo cách không giới hạn, các nhà nghiên cứu tại Vectara cho rằng rất khó tính chính xác tỷ lệ ảo giác.
"Bạn sẽ phải kiểm tra tất cả thông tin trên thế giới", TS Simon Hughes, nhà nghiên cứu, trưởng dự án tại Vectara, cho biết.

Một số tính năng của Apple Intelligence. (Ảnh: Apple).
Theo nhóm nghiên cứu, tỷ lệ ảo giác của chatbot cao hơn với những tác vụ khác. Thời điểm công bố nghiên cứu, công nghệ của OpenAI có tỷ lệ ảo giác thấp nhất (khoảng 3%), tiếp đến là Meta (khoảng 5%), Claude 2 của Anthropic (8%) và PaLM của Google (27%).
"Giúp hệ thống của chúng tôi trở nên hữu ích, trung thực và vô hại, bao gồm tránh tình trạng ảo giác, là một trong những mục tiêu cốt lõi của công ty", Sally Aldous, phát ngôn viên Anthropic cho biết.
Với nghiên cứu này, Hughes và các cộng sự muốn người dùng tăng cường cảnh giác với thông tin đến từ chatbot, kể cả dịch vụ cho người dùng phổ thông lẫn doanh nghiệp.
Bài viết liên quan
-

Nghiên cứu mới cho thấy chất độc của cóc sông Colorado có thể trở thành thuốc chống trầm cảm hiệu quả!
-

Ảo giác kỳ lạ khiến bạn thấy những người tý hon nhào lộn trong phòng
-
Phát hiện ma dược Maya gây ảo giác ở nơi bất ngờ nhất
-

Video ảo ảnh khiến dân mạng tranh cãi: Chú ngựa đang tiến lại gần hay đi ra xa?
-

Những vết mờ kỳ lạ người mắc chứng đau nửa đầu thường nhìn thấy là gì?
Công nghệ
-

Bí ẩn về đền thờ Baalbek, nơi công nghệ hiện đại không thể sao chép được quá trình xây dựng!
-

Tại sao bão thường theo hướng Tây -Tây Bắc?
-

Vì sao người Do Thái thông minh nhất thế giới?
-

Pháo đài khổng lồ ở sa mạc: Kỳ quan đáng kinh ngạc được con người tạo nên
-

Vật thể bí ẩn được cho là phi thuyền của người ngoài hành tinh đã tăng tốc để rời khỏi Hệ Mặt trời
-

Kỹ năng an toàn để sống sót khi ôtô bị tai nạn giao thông
AI - Trí tuệ nhân tạo
-

AI chỉ cần nghe tiếng gõ phím để đoán nội dung, đạt độ chính xác lên tới 95%
-
Công ty AI do Elon Musk tài trợ không dám tung phần mềm tạo văn bản mới vì quá nguy hiểm
-
Trí tuệ nhân tạo giúp Trung Quốc định vị được mỏ đất hiếm trải dài hơn 1.000km
-
Robot cũng phân biệt giới tính và chủng tộc
-
Thực hiện đúng những nguyên tắc này, robot sẽ không thể lật đổ con người
-
Nhìn con robot được AI hỗ trợ bổ trái cây như thế này, chợt nhận ra đôi tay con người mới kỳ diệu làm sao






Tiêu điểm
-
Dùng AI vẽ lại khuôn mặt của các nhân vật nổi tiếng trên khắp thế giới
-
Trí tuệ nhân tạo là gì? AI (artificial intelligence) là gì?
-
Top 11 ứng dụng trong quân sự đáng sợ nhất của Trí tuệ nhân tạo
-
Tìm hiểu về robot Sophia
-
Trí tuệ nhân tạo AGI là gì, mà khiến các nhà khoa học phải kinh sợ, làm hỗn loạn nội bộ OpenAI
-
Những ứng dụng thiết thực của AI trong cuộc sống
-
Công nghệ AI tái hiện màn biểu diễn của nam ca sĩ Hàn Quốc đã qua đời, chân thật đến ngỡ ngàng!







-

Khám phá khoa học
-

Sinh vật học
-

Khảo cổ học
-

Đại dương học
-

Thế giới động vật
-

Khoa học vũ trụ
-

Danh nhân thế giới
-

Ngày tận thế
-

1001 bí ẩn
-

Chinh phục sao Hỏa
-

Kỳ quan thế giới
-

Người ngoài hành tinh - UFO
-

Trắc nghiệm Khoa học
-

Khoa học quân sự
-

Lịch sử
-

Tại sao
-

Địa danh nổi tiếng
-

Hỏi đáp Khoa học
-

Công nghệ mới
-

Khoa học máy tính
-

Phát minh khoa học
-

AI - Trí tuệ nhân tạo
-

Y học - Sức khỏe
-

Môi trường
-

Bệnh Ung thư
-

Ứng dụng khoa học
-

Câu chuyện khoa học
-

Công trình khoa học
-

Sự kiện Khoa học
-

Thư viện ảnh
-

Video